Data Transformations with Databricks and DBT

In my previous post, Bigquery with DBT, we saw the power of using DBT (Data Build Tool) with Google BigQuery to perform our data transformations. But BigQuery is just one of many big data solutions currently available. Databricks is a another highly popular platform that offers a powerful data warehousing toolset. It provides a unified analytics platform that combines data engineering, data science, and business analytics, making it a versatile choice for data-driven organizations.
Databricks SQL allows us to interact with our data with SQL, meaning we can use DBT to perform our transformations. Databricks has many different tools for building your data pipeline. While DBT may not be the first solution that comes to mind in Databricks, it is still an excellent option. This post will also help example us compare Databricks SQL Warehouse with BigQuery, which is important when deciding which cloud data warehouse to choose.
Setup
I will only briefly go over some of the steps required to setup the sample data in Databricks for this example. I used the same data as the Bigquery with DBT post and simply moved it over to Azure Blob Storage. To obtain the CSV used in this example, follow the instructions in the previous post: Steps to Download Data.
Prerequisites
You will need a full version of Databricks running in a cloud platform. I chose the the Premium plan so that I could test their SQL Serverless warehouse. The community version does not give you a SQL Warehouse to connect your DBT project to. The cheapest Serverless SQL Warehouse option for this costs $2.80 an hour. However, it can spin up in 5-10 seconds. This allows us to turn off the Warehouse quickly when its not in use with no long cluster startup times.
Cloud Costs
I used Azure Databricks, taking advantage of the free trial for both both Azure and Databricks separately. I was able to keep costs well within the $200 trial amount for Azure. The Databricks trial is only 14 days and they give you very little insight into how much you are spending. Make sure to cancel the trial before you are charged.
Databricks is very expensive! If you do spin up your own Databricks watch your costs very closely. Make sure to set your clusters to
auto stopafter 30 minutes. Also, set budget alerts to make sure you’re not spending more than you think.
Creating our Bronze Table
Once the data is uploaded to Azure Blob Storage we can access it from Databricks. There are many different ways to load your data into Databricks. I chose to connect directly to Azure from Databricks Spark as this was the simplest at the time. It took several minutes to load the data and is most likely not the most performant option.
The following
Pythonsnippets were run in a Databricks notebook.
Setup Databricks Spark to Connect to Azure Blob Storage
The wasb(s) driver is being retired, please read more about the proper way to connect here: Connect to Azure Data Lake Storage. The storage account keys can be found on the Storage Account page in Azure. They are specific to the storage account you placed the CSV files in and not tied to a user.
 Storage Account
Storage Account
The key can be put into Databricks secrets or copied directly into your notebook (which is dangerous).
1
2
3
4
5
6
7
8
9
10
# These settings are needed to connect to Databricks
storage_account_name = "{your storage account name}"
container_name = "{your container name}"
base_path = f"wasbs://{container_name}@{storage_account_name}.blob.core.windows.net/cas/cas_csvs/"
# I stored my Azure Blob Storage Key in Databricks Secrets
# You can set this directly to your key (just a string), but that is not secure
storage_account_access_key = dbutils.secrets.get(scope="{your-scope}", key="{your-secret-key}")
file_type = "csv"
Those settings are then used to update our spark config.
1
2
3
spark.conf.set(
"fs.azure.account.key." + storage_account_name + ".blob.core.windows.net",
storage_account_access_key)
Now we can test if we are connected to our storage account. This should show the files in our blob storage if the setting we had were correct. If it fails, try double checking your Azure settings and key.
1
dbutils.fs.ls(base_path)
Use PySpark to Load Our Table
Next, we create our schema similiar to how we did when loading BigQuery. However, this time we will use PySpark. To view the whole schema, checkout the file in my Github Repo: example-schema.py.
1
2
3
4
5
6
7
8
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DecimalType
# Define schema
schema = StructType([
StructField("reference_pool_id", StringType()),
StructField("loan_identifier", StringType()),
StructField("monthly_reporting_period", StringType()),
...
Next, we use our schema and Azure path to load the CSVs into a dataframe. This may take several minutes.
1
2
3
4
5
df = spark.read.format(file_type) \
.schema(schema) \
.option("header", "false") \
.option("delimiter", "|") \
.load(base_path)
Now, we can save our table to the Unity Catalog of our choice. This will allow us to query it later without running this notebook using only a SQL Warehouse in Databricks.
1
df.write.saveAsTable(f"{catalog}.{schema}.cas_deals")
Verify Results in SQL Editor
Once the table is saved to the Unity Catalog using PySpark, it can be easily queried using the Databricks SQL Editor. This tool provides a user-friendly interface for running SQL queries on your data. The SQL Editor allows us to quickly check the structure and contents of the table, ensuring that our data has been loaded and transformed correctly.
1
SELECT * FROM catalog.schema.cas_deals LIMIT 10;
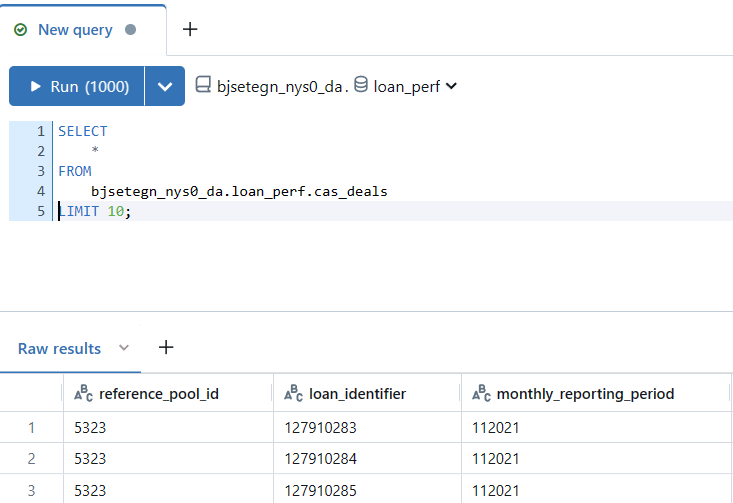 Bronze Table SQL Editor Results
Bronze Table SQL Editor Results
DBT
Now that our Bronze table is loaded, we can use DBT to make the transformations we need to create our Silver, and Gold tables.
This post will only cover the changes need to modify the existing BigQuery DBT project to Databricks.
Source Code
Connecting to Databricks
You will need to be running a SQL Warehouse in Databricks to be able to connect. Follow the instructions from the DBT Databricks repo for connecting your local environment to Databricks. Ensure you’re connected to Databricks from your DBT environment before proceeding: DBT - Databricks Connecting
Make sure to check the Connection Details of your Databricks SQL Warehouse when setting up your DBT Profile.
 Gold Table SQL Editor Results
Gold Table SQL Editor Results
Code Changes from BigQuery
A few small code changes were needed to make the same SQL run on Databricks. This highlights the fact that while DBT code is very portable, because its mostly just SQL, some small changes can be required between database types.
1
2
3
4
5
-- BigQuery
PARSE_DATE('%m%Y', monthly_reporting_period) AS reporting_period
-- Databricks Spark SQL
TO_DATE(monthly_reporting_period, 'MMyyyy') AS reporting_period
1
2
3
4
5
-- BigQuery
countif(scheduled_ending_balance > 0) as active_loan_count
-- Databricks Spark SQL
COUNT(CASE WHEN scheduled_ending_balance > 0 THEN 1 END) as active_loan_count,
DBT Run
Now that our SQL is updated, we can run dbt run to update the definitions in our data warehouse.
dbt runwill create the defined tables, views, and other objects in our data warehouse
Final Results
If dbt run was successful we can view our final materialized performance table in the Databricks SQL Editor. This demonstrates that it is more than possible to move your DBT code between data warehouses. Using DBT may be a great way to prevent vendor lockin for some of your data workflows.
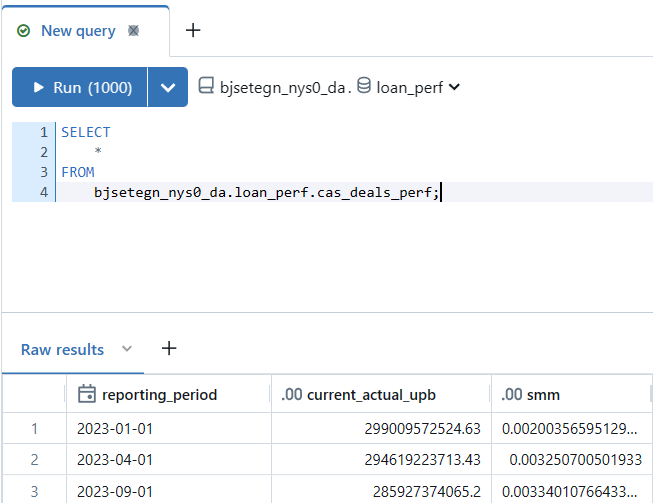 Gold Table SQL Editor Results
Gold Table SQL Editor Results